AuroraGPT
Sam Foreman 2024-09-04
- 🎯 AuroraGPT Goals
- 🧪 AuroraGPT: Open Science Foundation Models
- 📊 AuroraGPT Outcomes
- 🌌 Aurora
- 🤖 ALCF AI Testbed
- 👥 Team Leads
- 🤝 Teams
- 🦜 Model Training
- 🚀 Accelerating Dataset Processing at Scale for Training
- 🚀 Accelerating Dataset Processing at Scale for Training
- 📓 References
- 🎁 Extras
🎯 AuroraGPT Goals
AuroraGPT: General purpose scientific LLM Broadly trained on a general corpora plus scientific papers, texts, data
- Explore pathways towards a “Scientific Assistant” model
- Build with international partners (RIKEN, BSC, others)
- Multilingual English, 日本語, French, German, Spanish
- Multimodal: images, tables, equations, proofs, time series, graphs, fields, sequences , etc

Image from
Hannibal046/Awesome-LLM
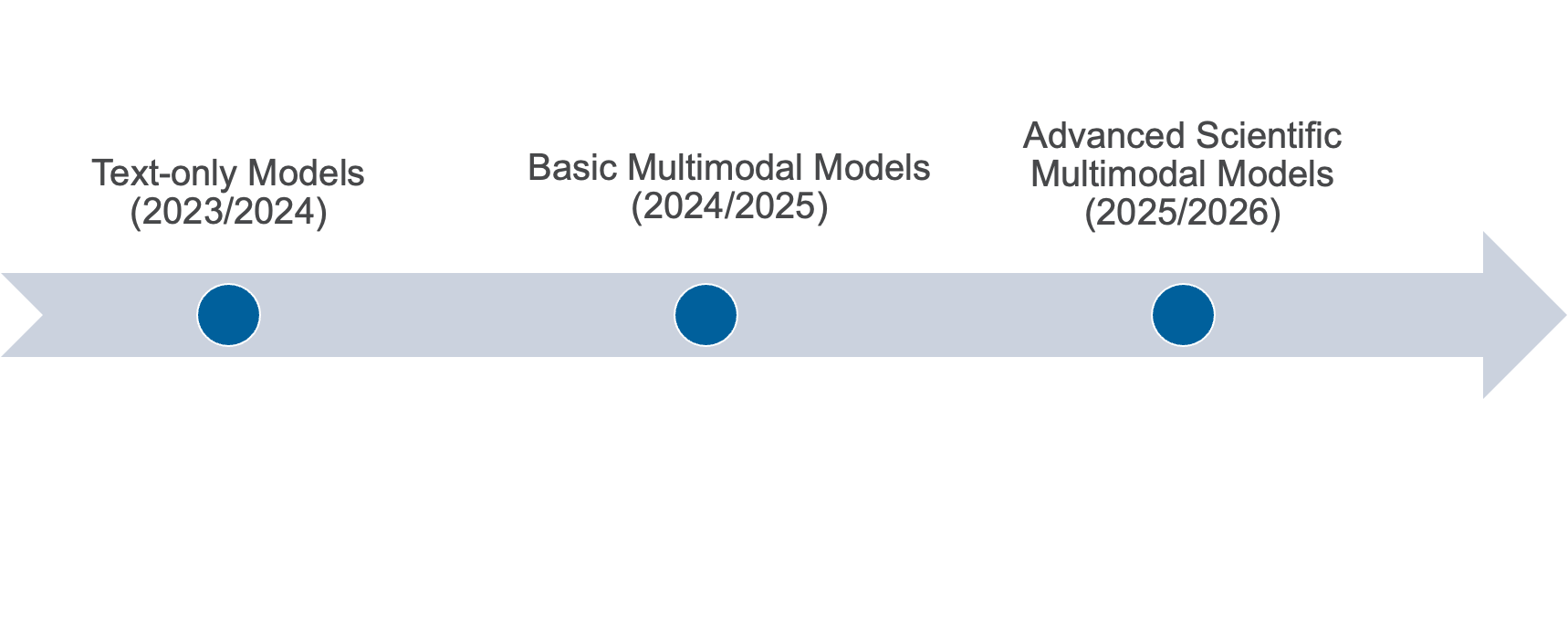
Figure 1: Credit to the entire AuroraGPT team for slides.
-
Here to talk about AuroraGPT, Argonne’s internal effort to build a general purpose scientific LLM, broadly trained on a general corpora of text + scientific {papers, text, data}
-
As part of this effort, we plan to…
- Explore pathways, build with international partners, multi-{lingual, modal}
-
Rough timeline of the project and deliverables:
- 202{3,4}: text-only models, plan to release a series of {7B, 70B, 1T} models
- 202{4,5}: Basic multi-modal models
- 202{5,6}: Advanced scientific multimodal models
🧪 AuroraGPT: Open Science Foundation Models

- AuroraGPT will be a publicly distributed, open source foundation model for open science
- Is being trained on:
- Scientific / engineering structured data
- General text, media, news, etc.
- Large amounts of low to medium quality data
- Much less high quality data (that is publicly available for use)
- This data is then cleaned, processed, de-duplicated and used for the initial pre-training phase of the model
- The vast majority of the overall compute is spent during this initial
pre-training phase
- This is the group I help to lead and will be talking a bit about today
- The initial pre-training phase is currently underway
- Eventually, given a bit of time, effort and magic, the model will be ready for fine-tuning and additional training for a variety of downstream tasks
- The pretrained model will then be handed off for additional
fine-tuning on a variety of downstream tasks
- Scientific discovery
- Accelerate scientific tasks
- Digital twins
- Inverse design
- Code optimization
- Accelerated simulations
- Autonomous experiments
- Co-design
- Becoming increasingly clear that LLMs have the potential to
drastically accelerate computational science
- We’ve seen this already for {GenSLMs, Weather / Climate / Earth Systems Modeling, Particle Physics, etc.}
📊 AuroraGPT Outcomes
- Datasets and data pipelines for preparing science training data
- Software infrastructure and workflows to train, evaluate and deploy LLMs at scale for scientific resarch purposes
- Evaluation of state-of-the-art LLM Models to determine where they fall short in deep scientific tasks and where deep data may have an impact
- Assessment of the approach of augmenting web training data with
two forms of data specific to science
- Full text scientific papers
- Structured scientific datasets (suitably mapped to narrative form)
- Research grade artifacts (models) for scientific community for adaptation for downstream uses
- Promotion of responsible AI best practices where we can figure them out
- International Collaborations around the long term goal of AGI for science
-
Deliverables:
- datasets, pipelines
- software infrastructure, workflows to interface with science applications
- checkpoints, models, logs, workbook, insights, etc.
-
Hope to understand:
- How different state-of-the-art models perform at different scientific tasks
- where deep data may have an impact
- feasibility of generically augmenting text with scientific structured data
-
Huge undertaking that will require large international collaborations around long term goal of AGI for science
-
Extra points:
- Well known that LLMs are good for non-consequential tasks
- Known to “hallucinate” and create false information
- Can this be mitigated reliably ??
🌌 Aurora
Table 1: Aurora Specs
| Racks | 166 |
| Nodes | 10,624 |
| CPUs | 21,248 |
| GPUs | 63,744 |
| NICs | 84,992 |
| HBM | 8 PB |
| DDR5c | 10 PB |

Figure 2: Aurora Fact Sheet
🤖 ALCF AI Testbed
- ALCF AI Testbed Systems are in production and available for allocations to the research community
- Significant improvement in time-to-solution and energy-efficiency for diverse AI for science applications.
- NAIRR Pilot
Up to 25X improvement for genomic foundation models with 6.5X energy efficiency

Figure 3: SambaNova SN-30: 2nd Gen, 8 nodes with 64 AI Accelerators

Figure 4: Graphcore Bow: generation accelerators: Pod-64 configuration with 64 accelerators

Figure 5: Cerebras: 2x CS-2 WSE with Memory-X and Swarm-X technologies

Figure 6: GroqRack: 9 nodes, 8 GroqChip v1.5 Tensor streaming processors accelerators per node
👥 Team Leads
Planning






Data

Models / Training


Evaluation



Post


Inference

Comms


Distribution

🤝 Teams
- Planning
- Data Prep
- Accumulate 20+ T tokens of high-quality scientific text and structured data
-
Models / Training
1 - Train (entirely from scratch) a series of models on publicly available data - Evaluation
- Skills, trustworthiness, safety, robustness, privacy, machine ethics
- Post-Training
- Fine-tuning, alignment
- Inference
- Model serving, API development / public-facing web services
- Distribution
- Licensing, generating and distributing artifacts for public consumption
- Communication
🦜 Model Training
✅ Goals
- Want training runs at scale to be:
- efficient
- stable
- reproducible
- This requires:
- robust data pipelines / file IO
- effectively overlapping compute with communication
- stability across network, filesystem, machine
- 3D / Multi-dimensional Parallelism strategies
- Large batch training
- Second order optimizers
- Sub-quadratic attention
- State space models
- Highly optimized GPU kernels
❌ Challenges
- Looong time to train, can be:
- weeks (even months) of continuous training
- order of magnitude longer than typical NN training jobs
- Stability issues:
- failures are expensive (but inevitable)
- stragglers common at scale
- Individual jobs are:
- fragile
- only as good as the worst rank
- one hang or bad worker can crash job
- network / filesystem / other-user(s) dependent
- Cost / benefits of different collective communication algorithms
- depend on optimized / efficient implementations
- Network performance
- Highly optimized GPU kernels
🚀 Accelerating Dataset Processing at Scale for Training
- To train a fixed model on trillions of tokens requires:
- Aggregating data from multiple different corpora (e.g. Reddit, StackExchange, GitHub, etc.)
- Sampling each training batch according to a fixed distribution across corpora
- Building indices that map batches of tokens into these files (indexing)
- The original implementation was slow, and designed to run on a single
device
- Major bottleneck when debugging data pipeline at scale
- Completely re-wrote an asynchronous, distributed implementation that significantly improves performance
🚀 Accelerating Dataset Processing at Scale for Training
- Completely re-wrote an asynchronous, distributed implementation that significantly improves performance


📓 References
- 🏡 samforeman.me:
- 🦜 Talks:
- See my other slides on:
- 🏎️
argonne-lcf/Megatron-DeepSpeedFor the largest of large language models. - 🍋
saforem2/ezpzDistributed training, ezpz. - 👀 See also:
❤️ Thank you!
🙏 Acknowledgements
This research used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357.
📑 Bibliography
- Refs:
- Wei et al. (2022)
- Animations from The Illustrated Transformer
Song, Shuaiwen Leon, Bonnie Kruft, Minjia Zhang, et al. 2023. DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery Through Sophisticated AI System Technologies. https://arxiv.org/abs/2310.04610.
Wei, Jason, Yi Tay, Rishi Bommasani, et al. 2022. Emergent Abilities of Large Language Models. https://arxiv.org/abs/2206.07682.
Yang, Jingfeng, Hongye Jin, Ruixiang Tang, et al. 2023. Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. https://arxiv.org/abs/2304.13712.
🎁 Extras
🚂 Loooooooooong Sequence Lengths

- Working with
Microsoft/DeepSpeed team to
enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details


Figure 7: Maximum (achievable) SEQ_LEN for both 25B and 33B models
(See: Song et al. (2023))
♻️ Life Cycle of the LLM
📝 Pre-training
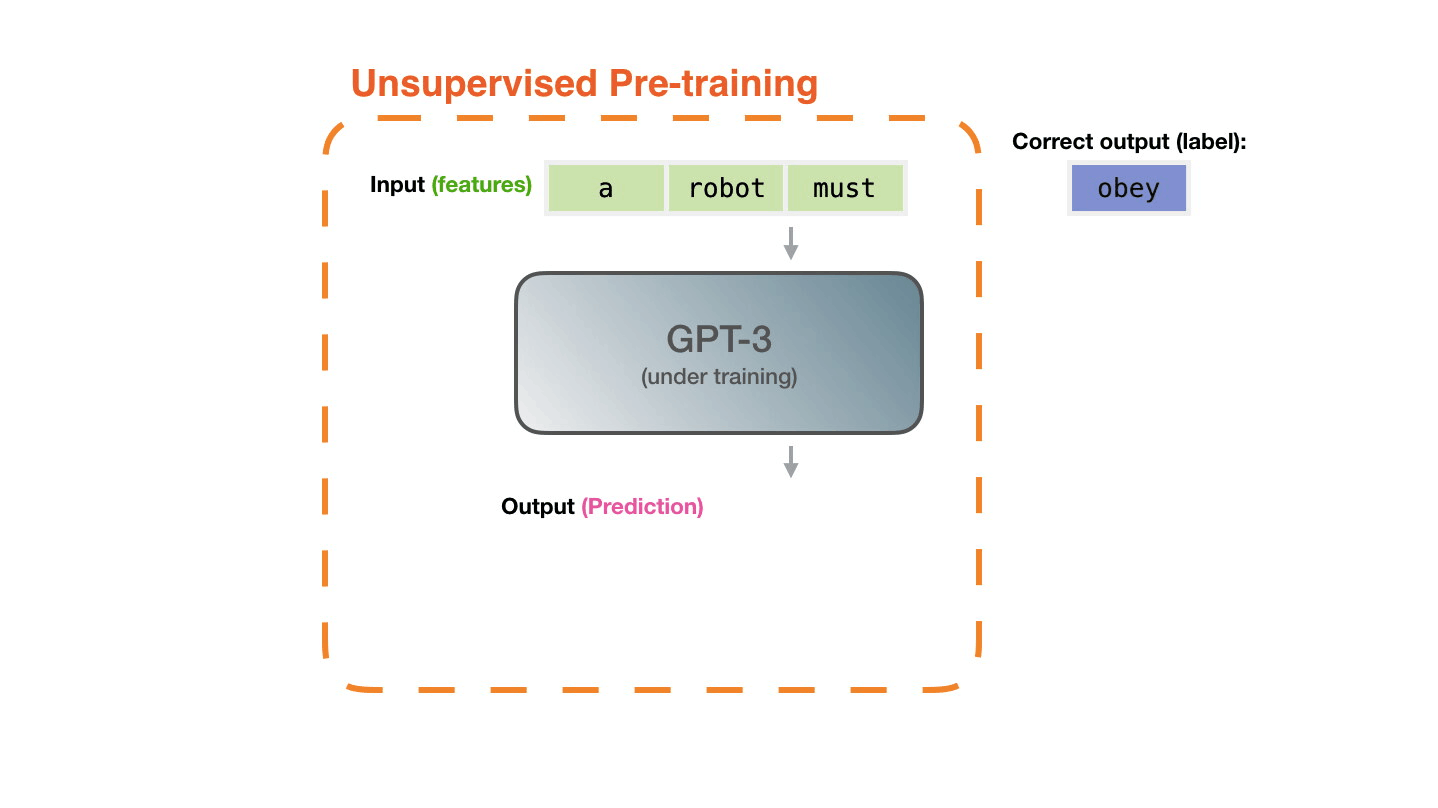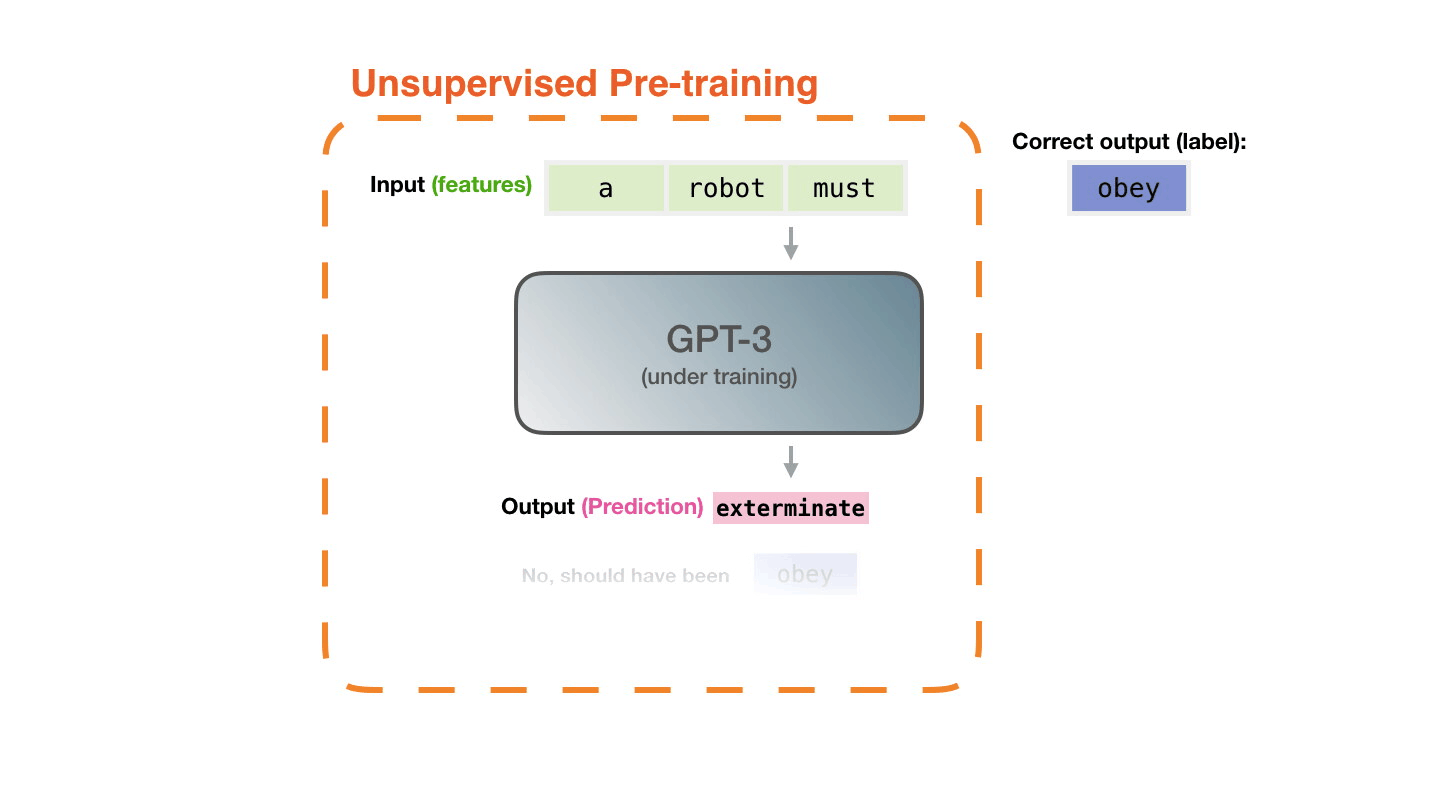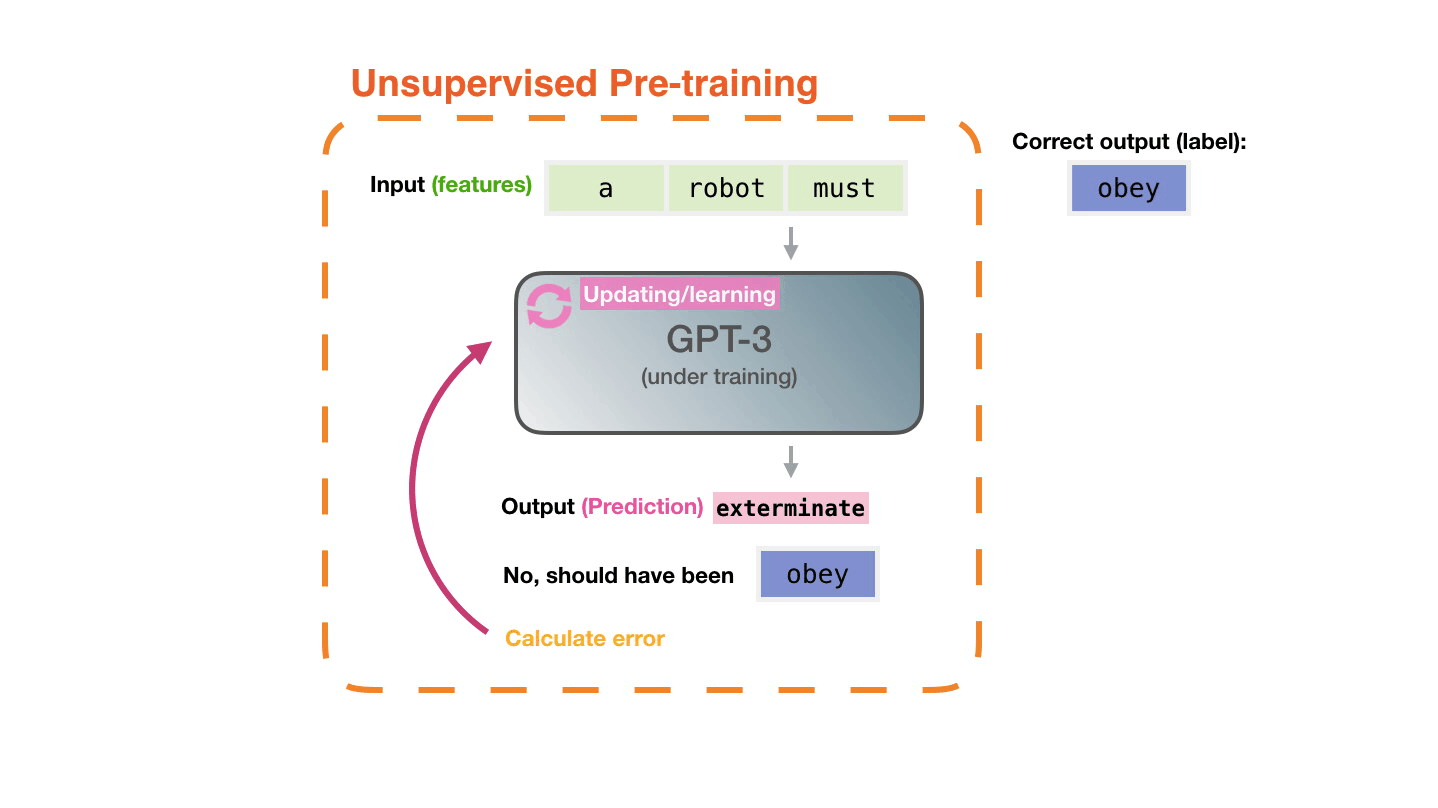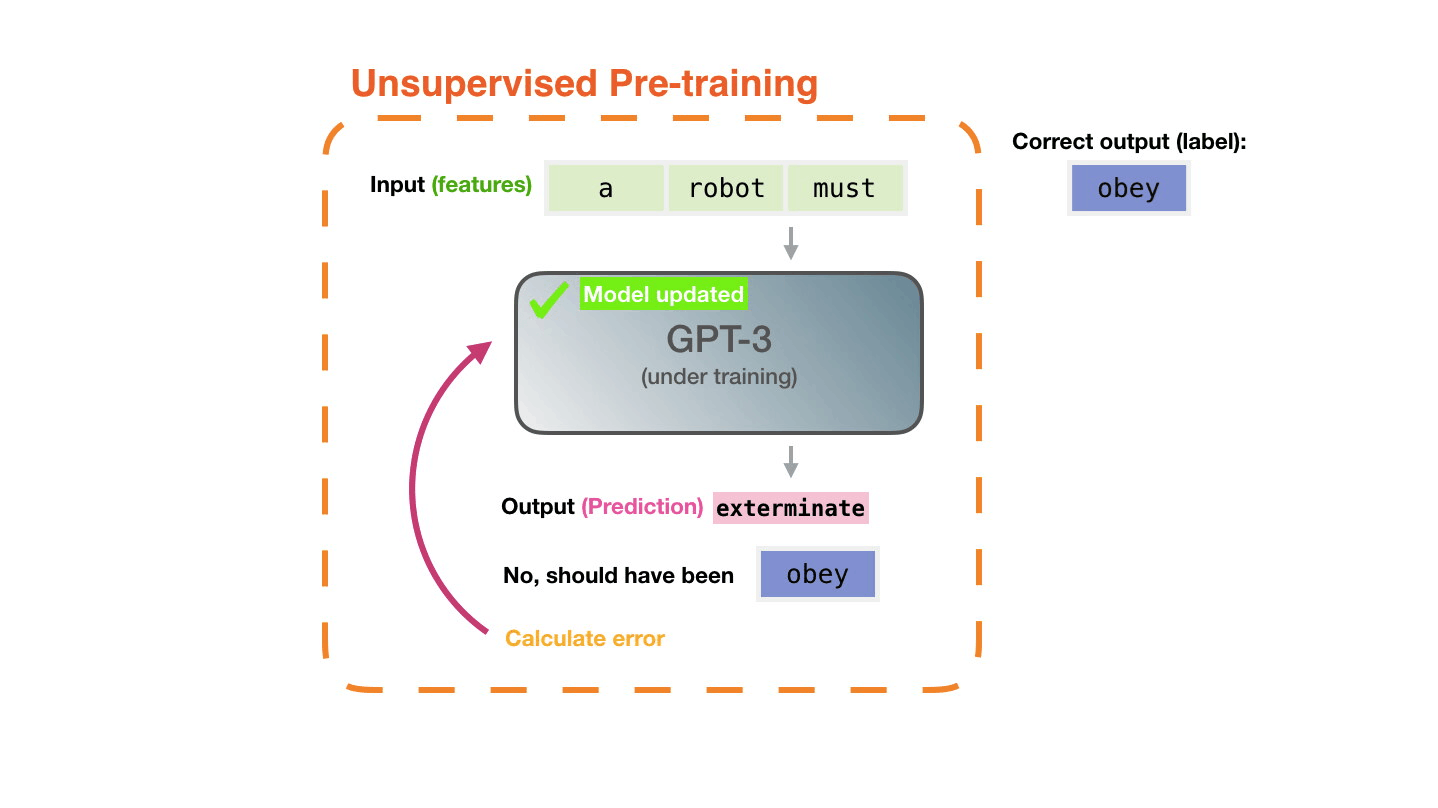
Figure 8: Pre-training: Virtually all of the compute used during pretraining phase
🎀 Fine-Tuning
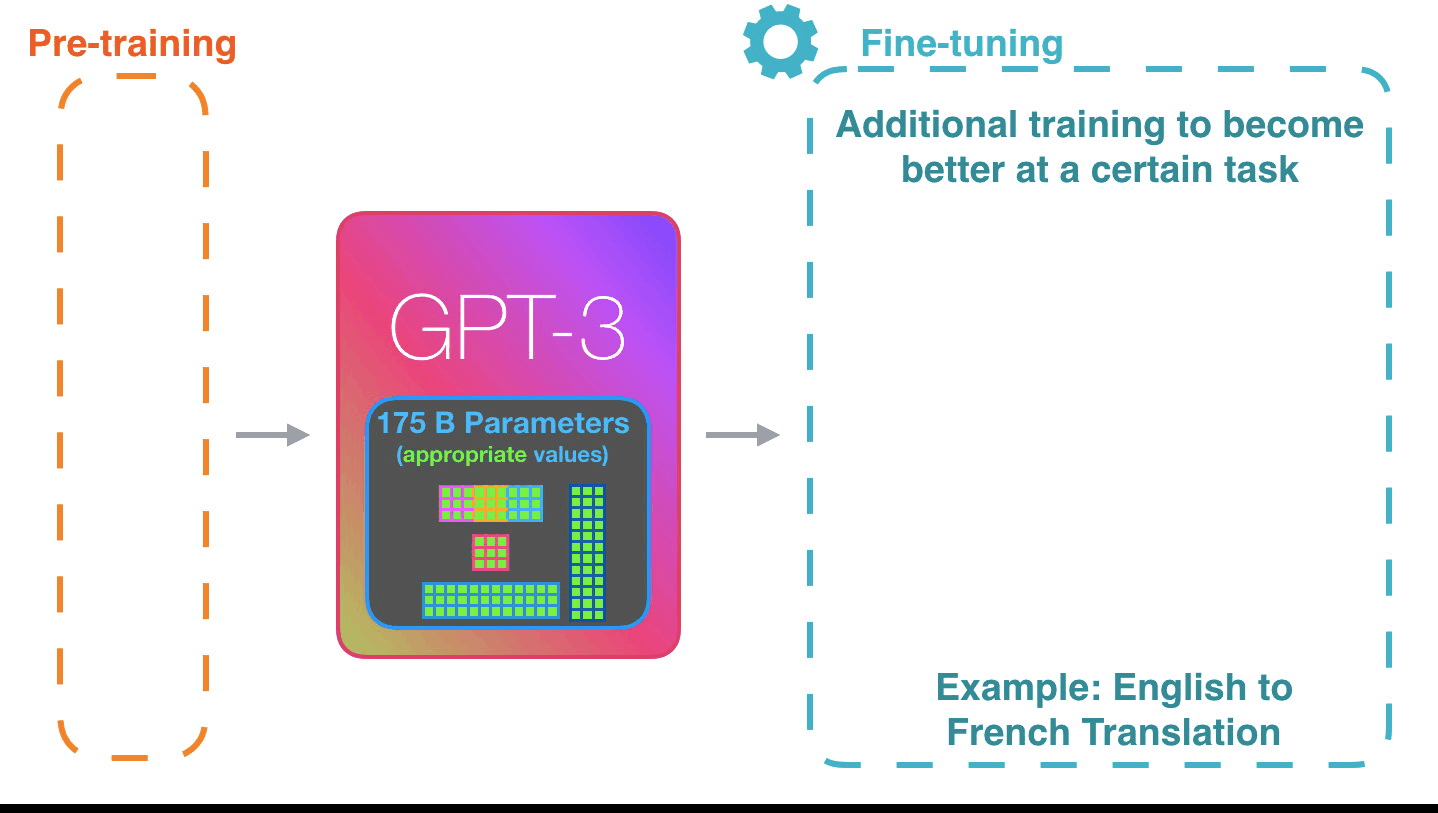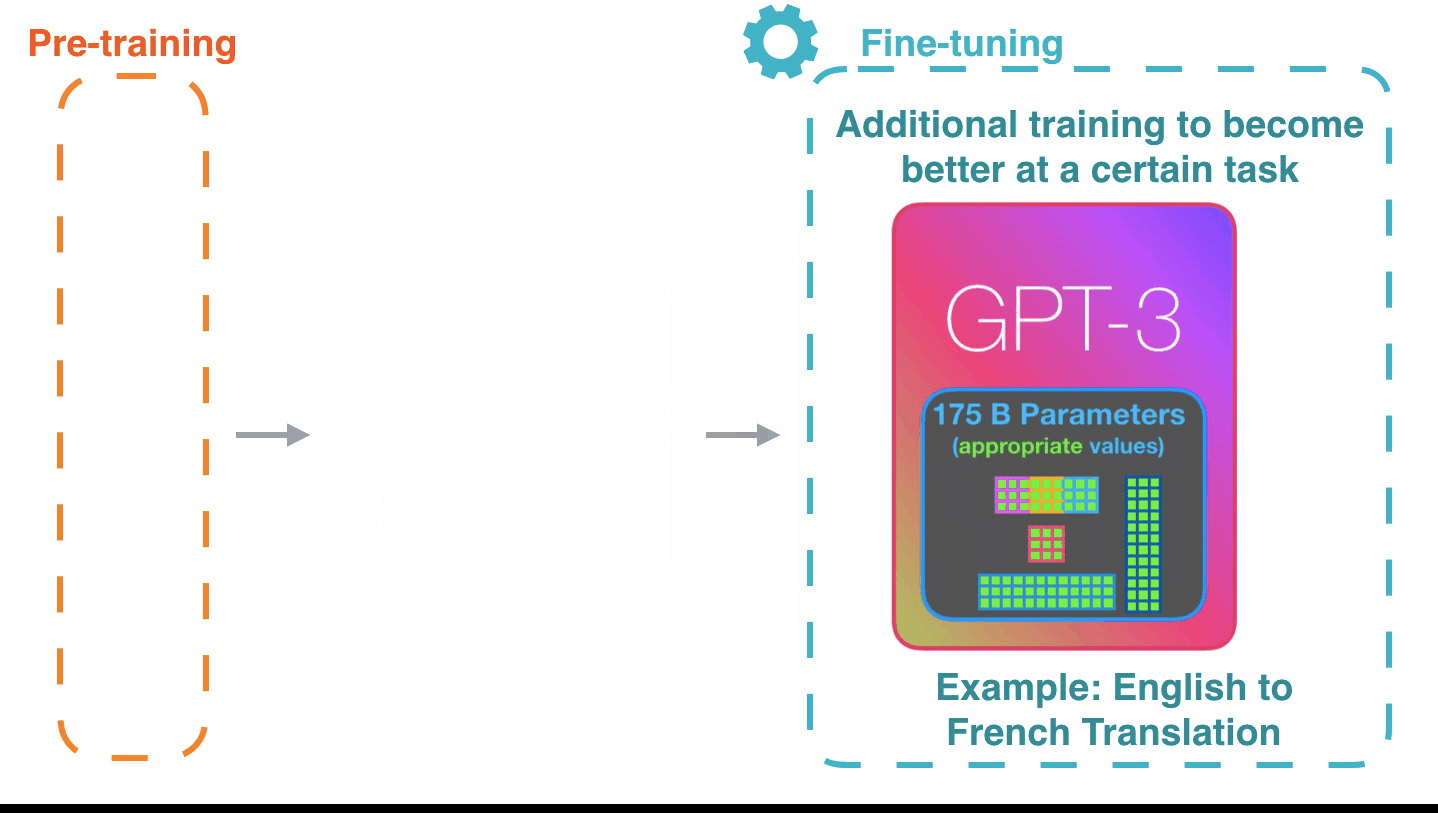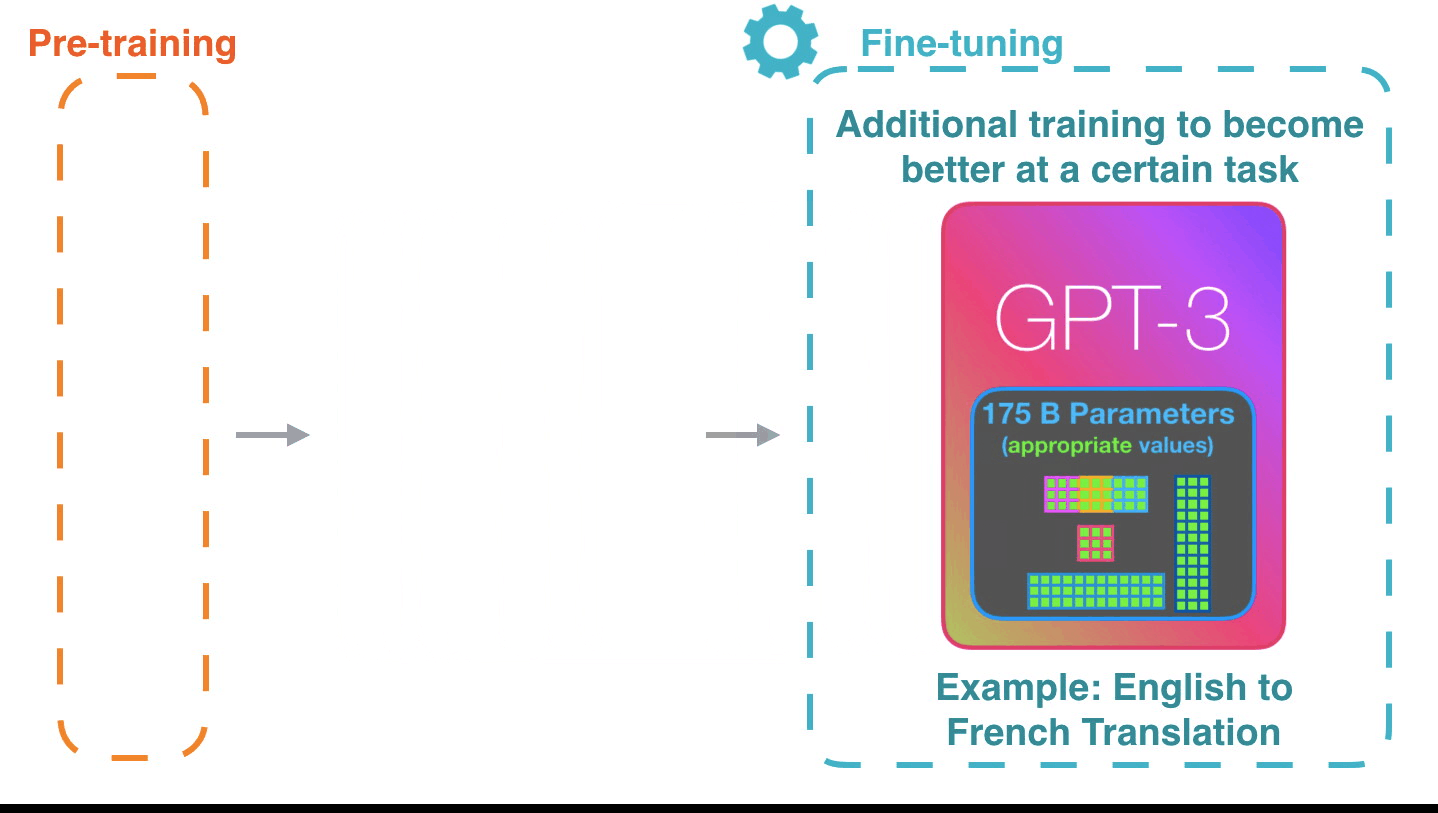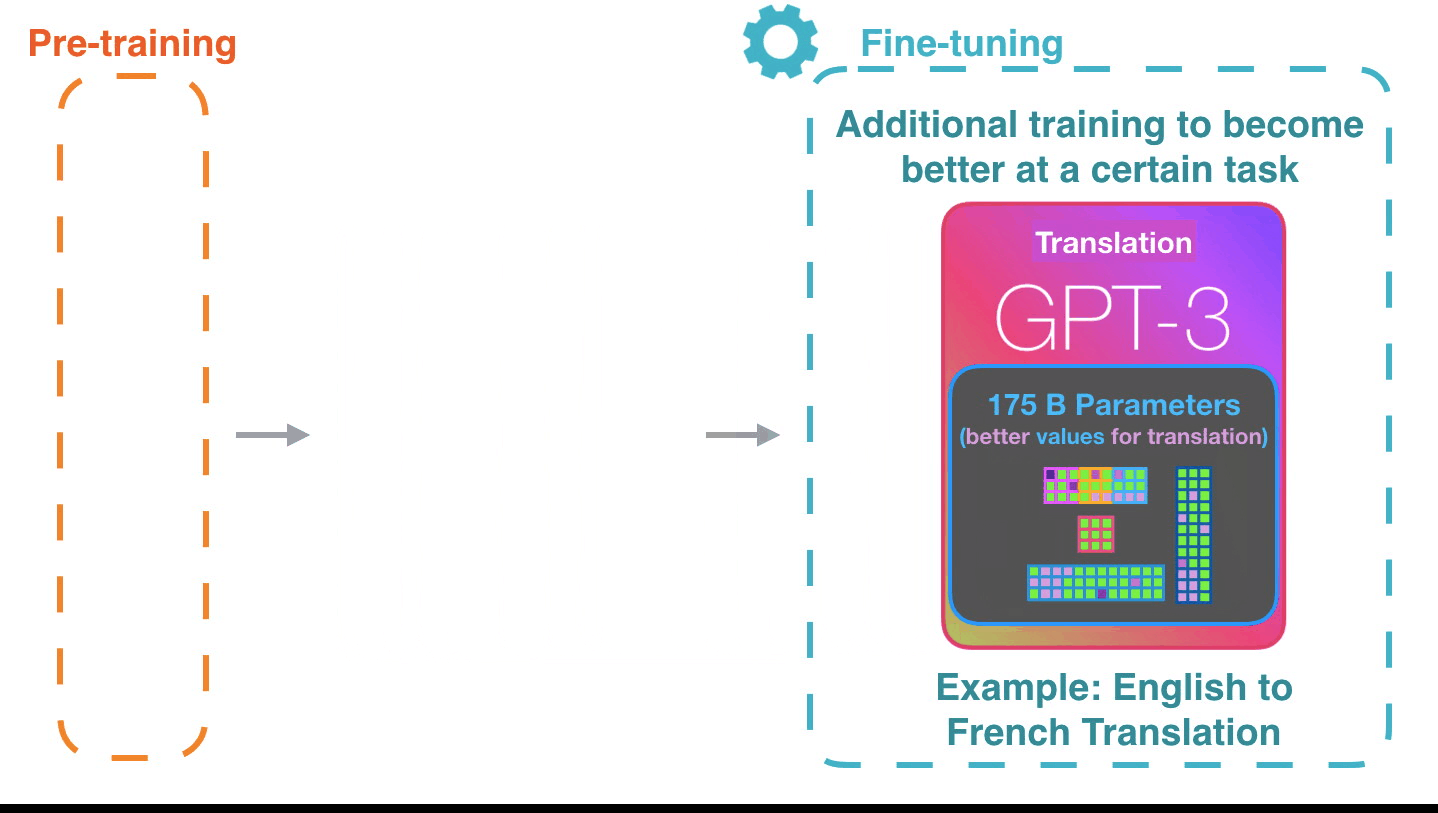
Figure 9: Fine-tuning: Fine-tuning actually updates the model’s weights to make the model better at a certain task.
🍎 Training LLMs

Figure 10: It’s hungry!

Figure 11: Visualization from Yang et al. (2023)
Footnotes
-
Co-led by: Venkat Vishwanath, Sam Foreman ↩