Production Pre-Training at Scale:
The Good, the Bad, and the Restarts
Lessons from AuroraGPT
Sam Foreman1, Nathan Nichols, Varuni Sastry, Samuel Wheeler, Khalid Hossain, Huihuo Zheng, Murali Emani, Filippo Simini, Marieme Ngom, Ethan Wong, Venkat Vishwanath
2026-06-03


Why SophiaG: large-batch stability at 50M tok/batch

256N · GBS=6,144 · 50M tok/batch. SophiaG is the only one that stays in the low-loss band with bounded grad norms.

2B reference + torchtitan overlay

Same MDS trajectory as the reference chart, with the torchtitan 256N
production run drawn on the same axes: starts inside the MDS pretrain
region and tracks the same loss-vs-tokens curve.
2B loss: MDS full trajectory vs torchtitan

256N / GBS=6,144. At matched tokens, δ ≈ 0.02 — within run-to-run noise. The cutover preserved training behavior.
2B eval: MDS reference vs torchtitan





Data:
docs/evals/agpt/2b,
production run:
docs/production/agpt/2b
20B eval: all-production overlay (2B + 20B)





Data:
docs/evals/agpt/20b,
production run:
docs/production/agpt/20b
ezpz yeet: Efficiently Running 50k Python Processes
| Nodes | yeet (s) | First-step (s) | Per-node (ms) |
|---|---|---|---|
| 8 | 69.7 | 29.3 | 8,712 |
| 16 | 89.7 | 31.6 | 5,606 |
| 32 | 89.2 | 20.9 | 2,788 |
| 64 | 91.2 | 34.6 | 1,425 |
| 128 | 110.4 | 30.5 | 862 |
| 256 | 132.9 | 37.6 | 519 |
| 512 | 174.5 | 44.5 | 341 |
| 1024 | 255.4 | 60.8 | 249 |
| 2048 | 421.4 | 94.8 | 206 |
| 4096 | 750.6 | 194.0 | 183 |

Two regimes. 8–64 nodes extract-bound (~70–91s flat, per-node cost falls 8.7s → 1.4s); ≥128 nodes broadcast-bound, each 2× in nodes adds ~1.5–1.8× wall-clock.
Full write-up: sam.onl/posts/2026/05/01
LR-finder — exponential sweep, blow-up / 10
Smith 2015 / Gugger: exponentially ramp LR over ~10% of training, record EMA-smoothed loss, pick LR at the steepest descent (or blow-up point / 10 as a conservative default).

Cross-optimizer sweep on Aurora (Intel Max 1550, 2 nodes / 24 XPUs).
Source:
docs/experiments/lr-finder
LR-finder — 2B sweep + optimal LR per config


Optimal LR per config. AdamW most tolerant; SophiaG ~10× lower.
Findings: AdamW most LR-tolerant; SophiaG needs ~10× lower LR; SophiaG + Muon both break at 80B (bf16 overflow in Newton-Schulz / Hessian estimate on 9216-dim matrices).
Optimizer speedrun — Mano LR sweep, WSM, Schedule-Free
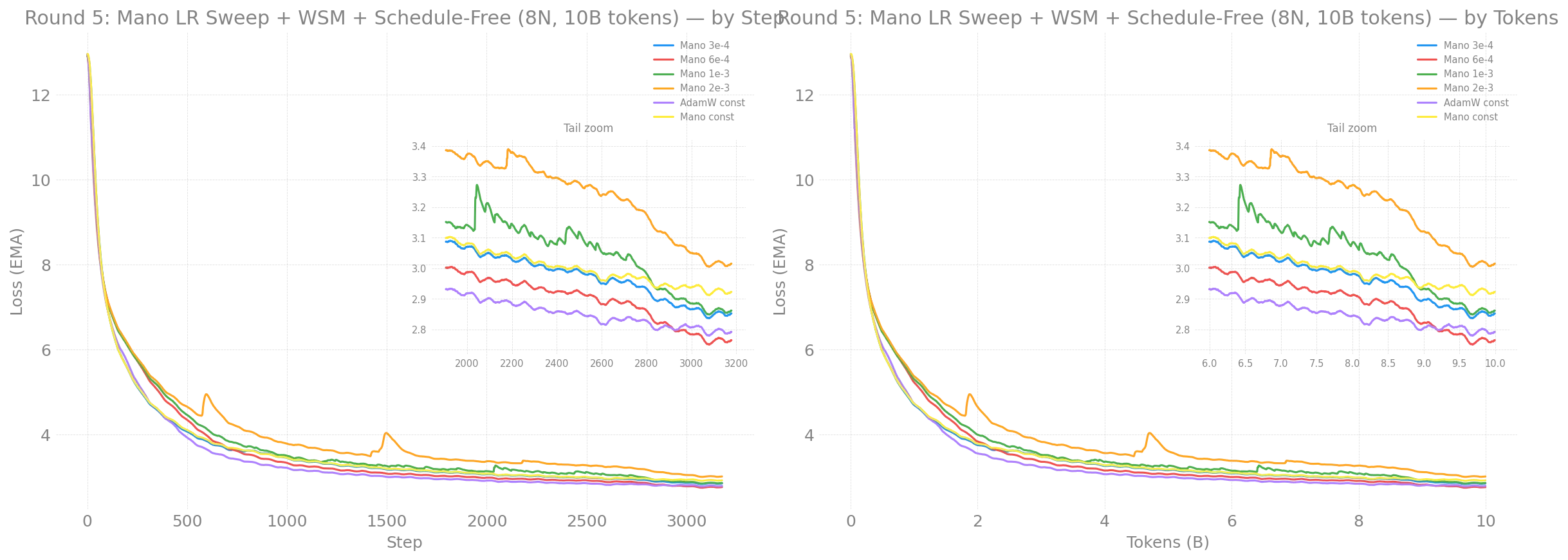
Round 5 speedrun: 8 nodes, GBS=384, 10B tokens. Dual view — by step and by tokens consumed.
Headline numbers (Round 3, 10B tokens / 8N / GBS=384):
| Rank | Config | Loss | TPS/GPU |
|---|---|---|---|
| 1 | AdamW | 2.711 | 7,354 |
| 2 | AdamW + QK-Norm | 2.720 | 7,480 |
| 3 | Mano + QK-Norm | 2.854 | 7,346 |
| 4 | Mano | 2.875 | 7,429 |
| 5 | Muon | DNF | — |
AdamW wins at GBS=384. Mano lands ~0.16 behind — LR finder was tuned at GBS=48 and the manifold update under-shoots at large batch.
Silent bug #1 — the smoking gun
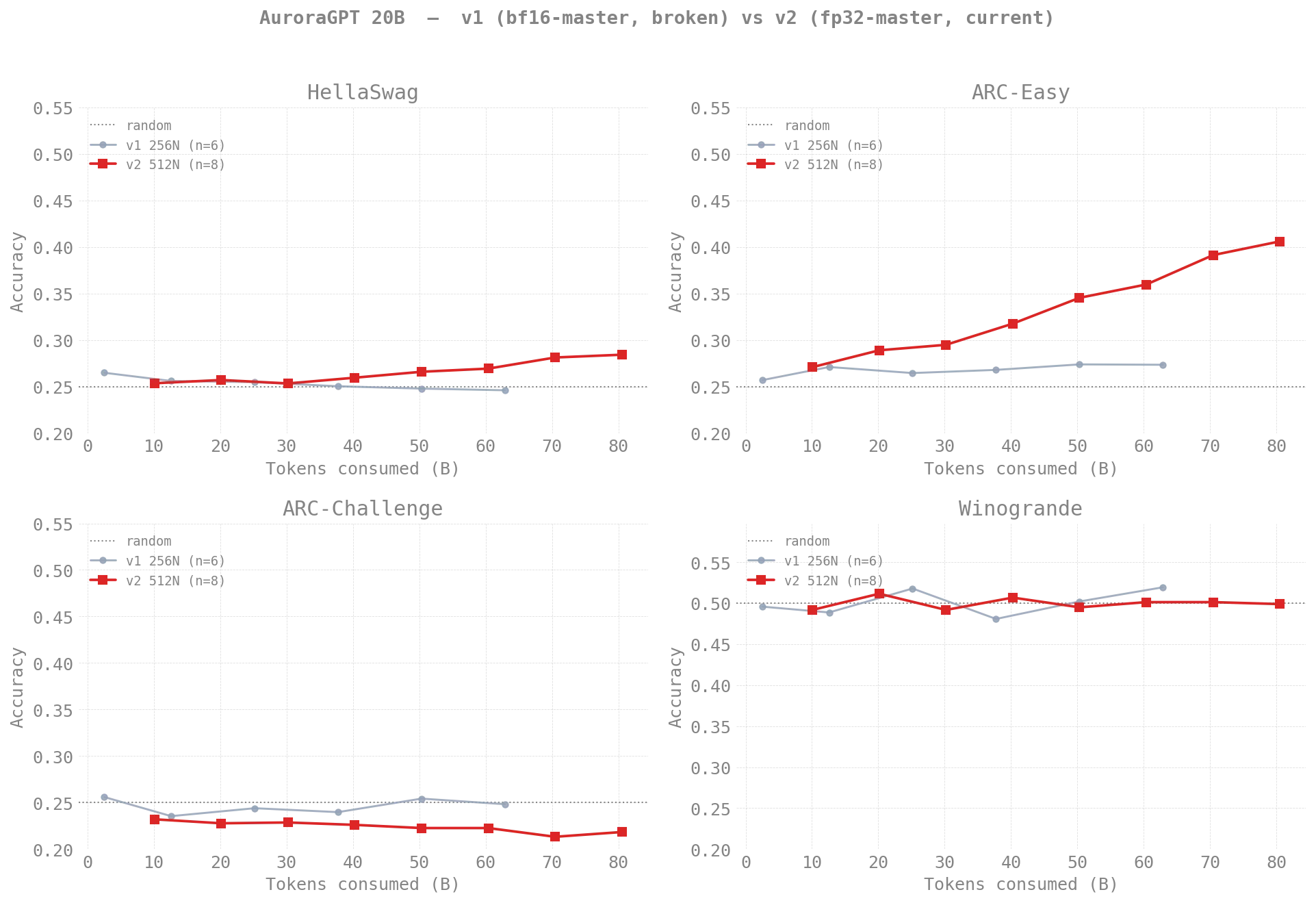
v1 (bf16 master, 256N): ARC-Easy 0.27 flat across 2,500 steps · v2
(fp32 master, 512N): ARC-Easy 0.27 → 0.44 by step 800 · HellaSwag breaking
out.
Lesson: loss looks like training. lm-eval is the only ground truth for “is the model actually learning?” Add a periodic eval gate.
Footnotes
-
Argonne National Laboratory ↩
-
And away from argonne-lcf/Megatron-DeepSpeed! ↩
-
allenai/olmo-mix-1124 — 0 → 4.67T tokens ↩
-
allenai/dolmino-mix-1124 — 4.67T → 7.06T tokens ↩
-
NVIDIA/{Nemotron-CC-Math-v1, Code-CC-v1} — 7.06T → 7.77T tokens ↩
-
Llama 3 herd of models (Meta AI, 2024), §3.3.2 (Training reliability) ↩
-
OPT-175B chronicles + dev log (Zhang et al., 2022) ↩
-
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model (BigScience, 2022) ↩
-
GLM-130B: An Open Bilingual Pre-Trained Model (Zeng et al., ICLR 2023) ↩