AuroraGPT: Training Foundation Models on Supercomputers
Sam Foreman 2025-12-16
- 🧰 AuroraGPT: Toolbox
- 👥 Team Leads
- 🤝 Teams
- 🏋️ Challenges
- 🧬 MProt-DPO
- 🌎 AERIS (2025)
- 📓 References
- ❤️ Acknowledgements
- Extras
🧰 AuroraGPT: Toolbox
- Datasets and data pipelines (how do we deal with scientific data?)
- Software infrastructure and workflows (scalable, robust, extensible)
- Evaluation of state-of-the-art LLM Models (how do they perform on scientific tasks?)
👥 Team Leads
Planning






Data

Training


Evaluation



Post


Inference

Comms


Distribution

🤝 Teams
- Planning
- Data Prep
- Accumulate 20+ T tokens of high-quality scientific text and structured data
-
Models / Training
1 - Train (entirely from scratch) a series of models on publicly available data - Evaluation
- Skills, trustworthiness, safety, robustness, privacy, machine ethics
- Post-Training
- Fine-tuning, alignment
- Inference
- Model serving, API development / public-facing web services
- Distribution
- Licensing, generating and distributing artifacts for public consumption
- Communication
🏋️ Challenges
This is incredibly difficult in practice, due in part to:
- Brand new hardware, architecture, software
- Lack of native support in existing frameworks (though getting better!)
- General system stability
+10k Nodes +100k XPUs- network performance
- file system stability (impacted by other users !)
- many unexpected difficulties occur at increasingly large scales
- Combinatorial explosion of possible configurations and experiments
- {hyperparameters, architectures, tokenizers, learning rates, …}
💾 AuroraGPT: Training
- To train a fixed model on trillions of tokens requires:
- Aggregating data from multiple different corpora
(e.g. ArXiv, Reddit, StackExchange, GitHub, Wikipedia, etc.) - Sampling each training batch according to a fixed distribution across corpora
- Building indices that map batches of tokens into these files (indexing)
- Aggregating data from multiple different corpora
The original implementation was slow:
- Designed to run serially on a single device
- Major bottleneck when debugging data pipeline at scale
🍹 AuroraGPT: Blending Data, Efficiently
- 🐢 Original implementation:
- Slow (serial, single device)
- ~ 1 hr/2T tokens
- 🐇 New implementation:
- Fast! (distributed, asynchronous)
- ~ 2 min/2T tokens (30x faster !!)

Figure 1: Time spent preparing 2T tokens
📉 Training AuroraGPT-7B on 2T Tokens
📉 Training AuroraGPT-2B on 7T Tokens


🌀 Sequence-Window-Pipeline Parallelism SWiPe
SWiPeis a novel parallelism strategy for Swin-based Transformers- Hybrid 3D Parallelism strategy, combining:
- Sequence parallelism (
SP) - Window parallelism (
WP) - Pipeline parallelism (
PP)
- Sequence parallelism (

Figure 10

Figure 11: SWiPe Communication Patterns
🚀 AERIS: Scaling Results

Figure 12: AERIS: Scaling Results
- 10 EFLOPs (sustained) @ 120,960 GPUs
- See (Hatanpää et al. (2025)) for additional details
- arXiv:2509.13523
🌪️ Hurricane Laura
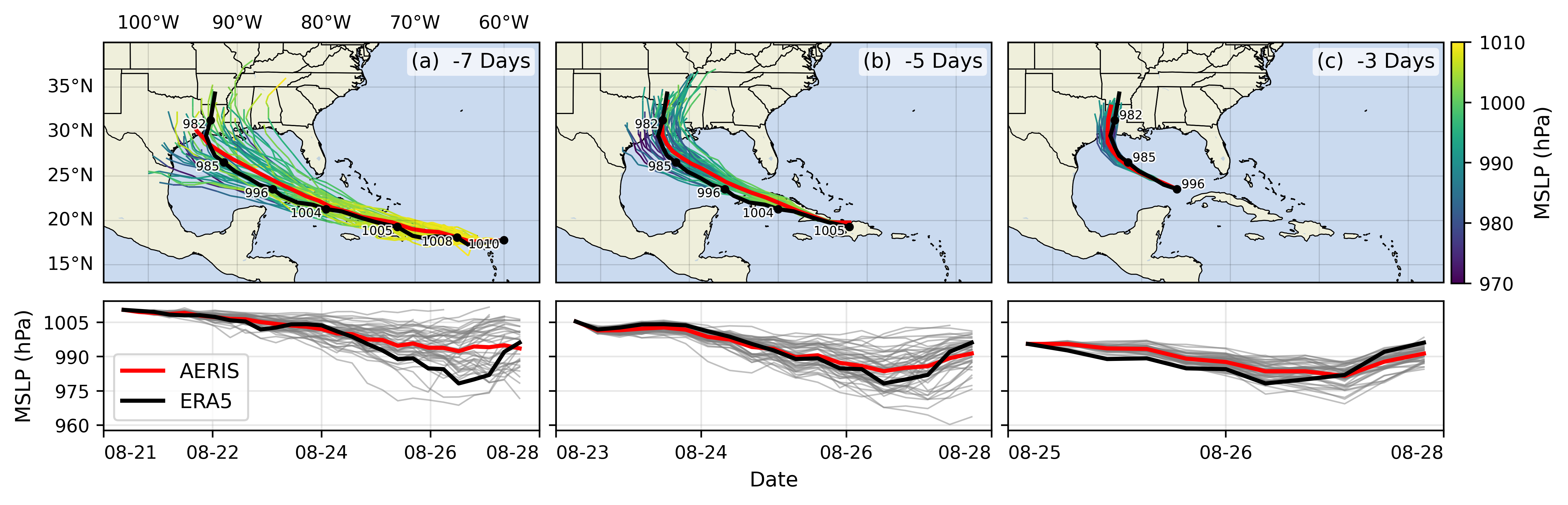
Figure 13: Hurricane Laura tracks (top) and intensity (bottom). Initialized 7(a), 5(b) and 3(c) days prior to 2020-08-28T00z.
📓 References
Dharuman, Gautham, Kyle Hippe, Alexander Brace, et al. 2024. “MProt-DPO: Breaking the ExaFLOPS Barrier for Multimodal Protein Design Workflows with Direct Preference Optimization.” Proceedings of the International Conference for High Performance Computing, Networking, Storage, and Analysis (Atlanta, GA, USA), SC ’24. https://doi.org/10.1109/SC41406.2024.00013.
Hatanpää, Väinö, Eugene Ku, Jason Stock, et al. 2025. AERIS: Argonne Earth Systems Model for Reliable and Skillful Predictions. https://arxiv.org/abs/2509.13523.
Price, Ilan, Alvaro Sanchez-Gonzalez, Ferran Alet, et al. 2024. GenCast: Diffusion-Based Ensemble Forecasting for Medium-Range Weather. https://arxiv.org/abs/2312.15796.
Song, Shuaiwen Leon, Bonnie Kruft, Minjia Zhang, et al. 2023. DeepSpeed4Science Initiative: Enabling Large-Scale Scientific Discovery Through Sophisticated AI System Technologies. https://arxiv.org/abs/2310.04610.
❤️ Acknowledgements
This research used resources of the Argonne Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC02-06CH11357.
Extras
Footnotes
-
Co-led by: Venkat Vishwanath, Sam Foreman ↩