AuroraGPT: Training Foundation Models on Supercomputers
Sam Foreman — Argonne National Laboratory 2025-12-16
samforeman.me/talks/2025/12/16/slides


Team Leads
Planning
 Rick Stevens (lead)
Rick Stevens (lead) Ian Foster
Ian Foster Rinku Gupta
Rinku Gupta Mike Papka
Mike Papka Arvind Ramanathan
Arvind Ramanathan Fangfang Xia
Fangfang XiaData
Ian Foster Robert Underwood
Robert UnderwoodTraining
 Venkat Vishwanath
Venkat Vishwanath Sam Foreman
Sam ForemanEvaluation
 Franck Cappello
Franck Cappello Sandeep Madireddy
Sandeep Madireddy Bo Li
Bo LiPost
 Eliu Huerta
Eliu Huerta Azton Wells
Azton WellsInference
 Rajeev Thakur
Rajeev ThakurComms
 Charlie Catlett
Charlie Catlett David Martin
David MartinDistribution
 Brad Ullrich
Brad UllrichAuroraGPT: Blending Data, Efficiently

Figure: Time spent preparing 2T tokens
Training AuroraGPT-7B on 2T Tokens

Train (grey) and validation (blue) loss vs number of consumed training tokens for AuroraGPT-7B on 64 nodes of Aurora.
Training AuroraGPT-2B on 7T Tokens
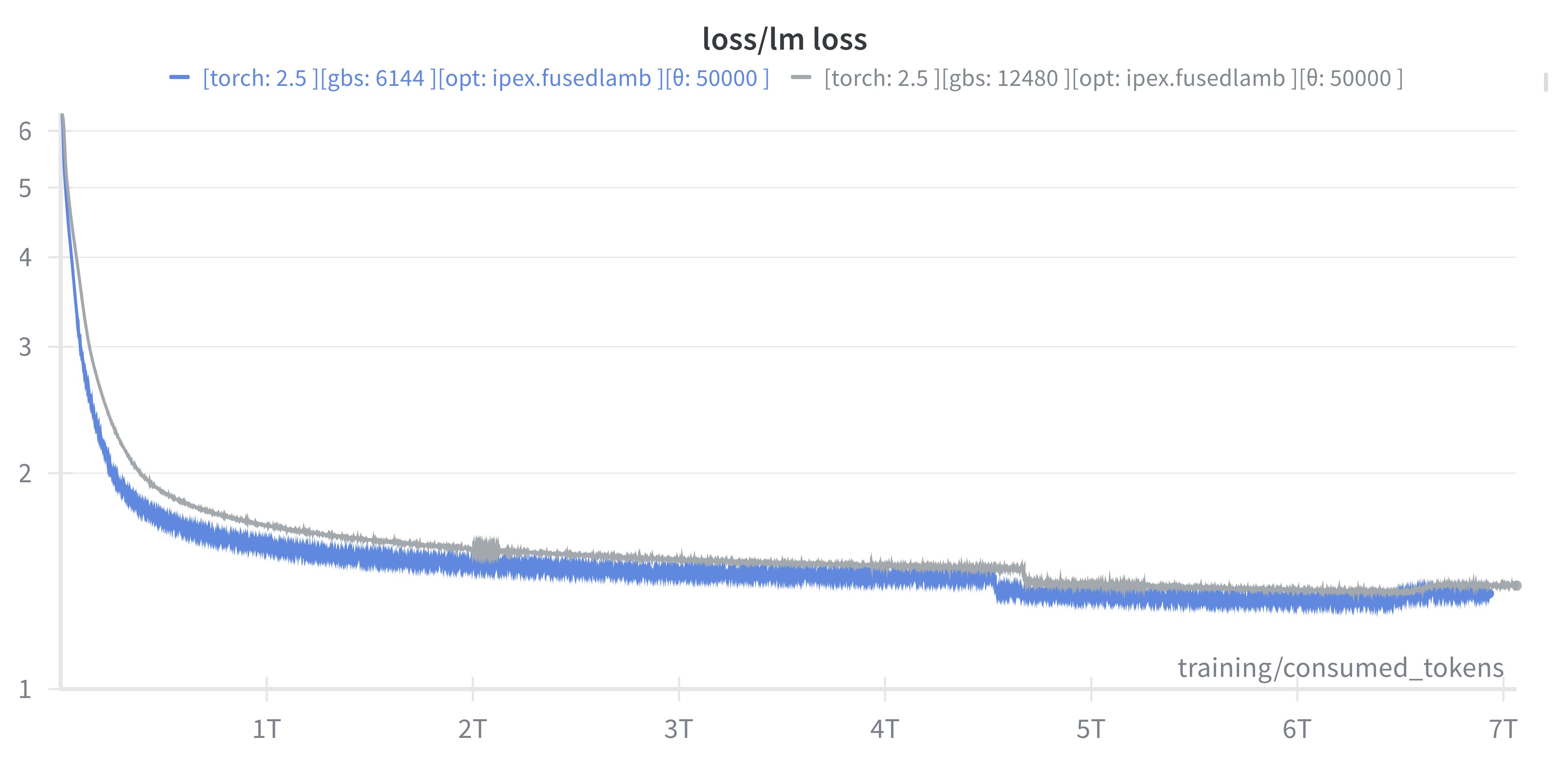
(new) Loss vs number of consumed training tokens for AuroraGPT-2B on 256 (blue) and 520 nodes (grey) of Aurora. Both runs show stability through 7T tokens.
Scaling Results (2024)

Figure: Scaling results for 3.5B model across ~38,400 GPUs
MProt-DPO: Scaling Results
3.5B model

7B model
Loooooooooong Sequence Lengths

- Working with Microsoft/DeepSpeed team to enable longer sequence lengths (context windows) for LLMs
- See my blog post for additional details

25B

33B
Maximum (achievable) SEQ_LEN for both 25B and 33B models (See: Song et al. 2023)
AERIS (2025)


Pixel-level Swin diffusion transformer in sizes from [1–80]B
High-Level Overview of AERIS
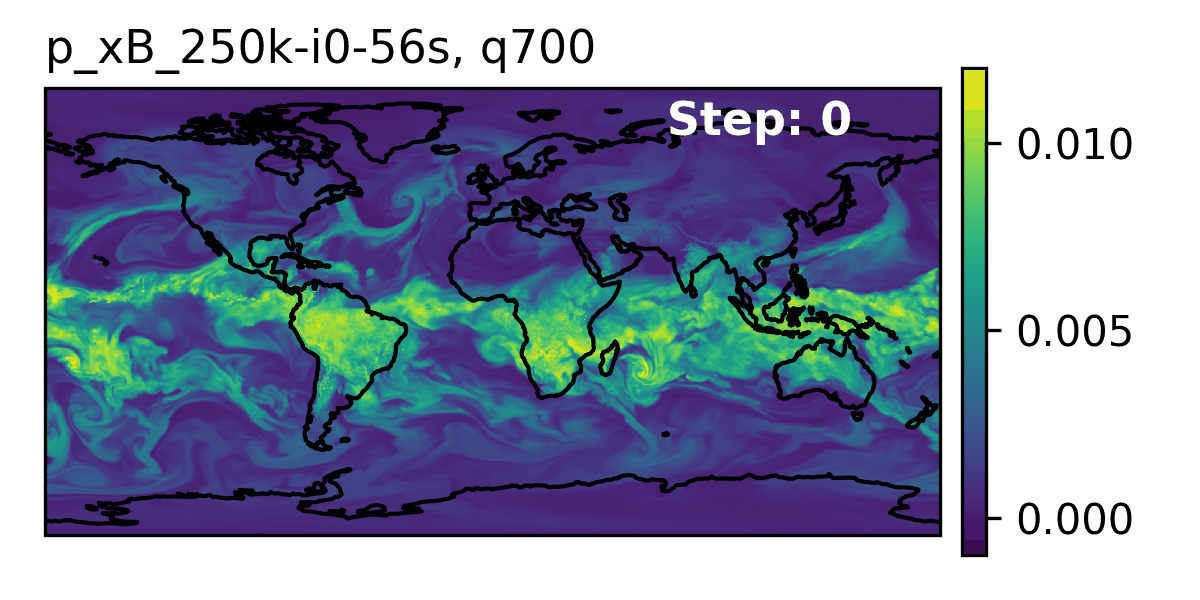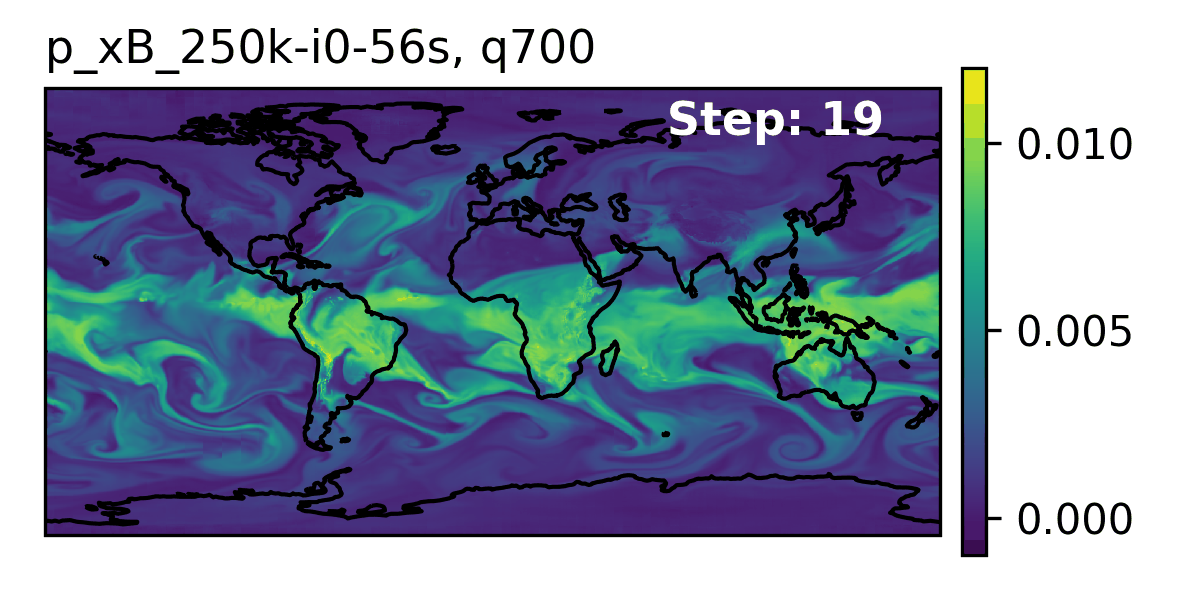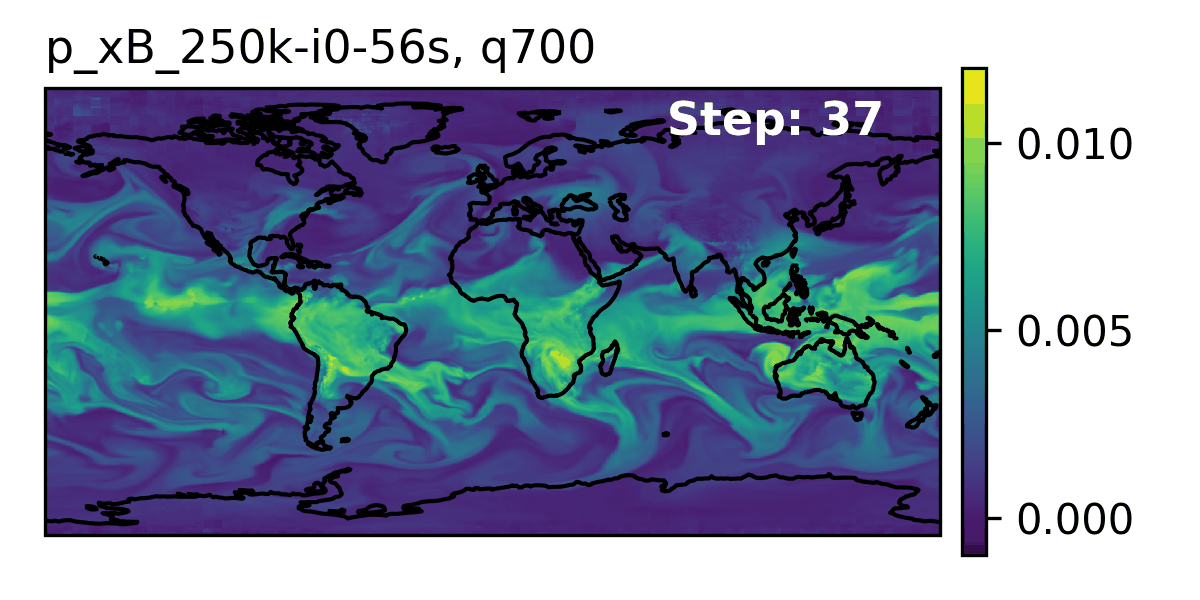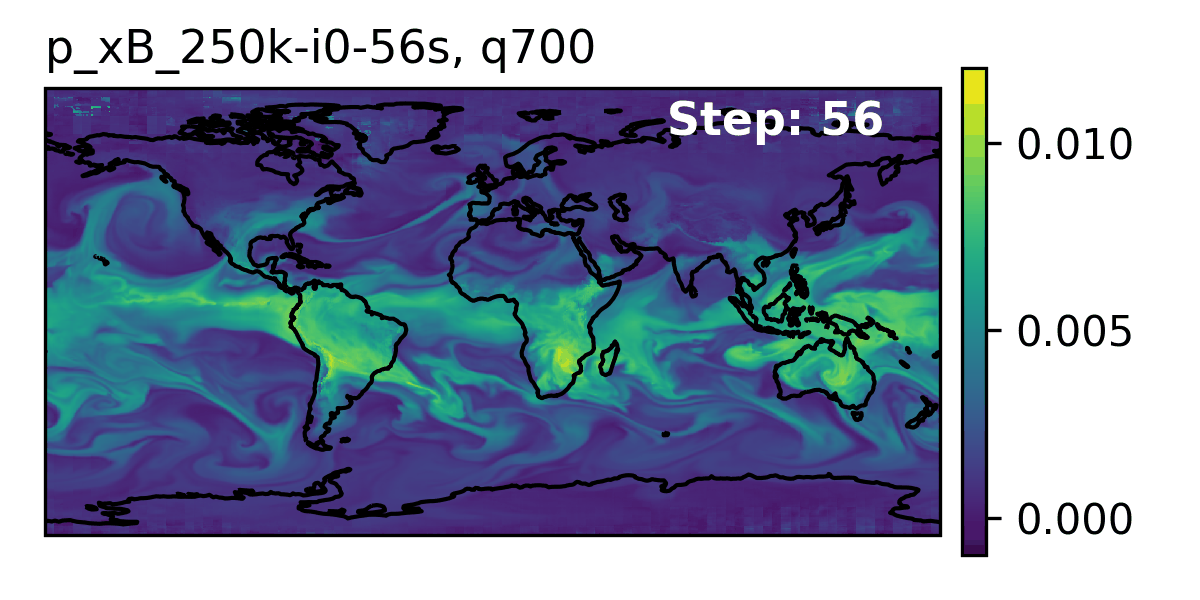
Rollout of AERIS model, specific humidity at 700m.
Transitioning to a Probabilistic Model

Reverse diffusion with the input condition, individual sampling steps , the next time step estimate and the target output.
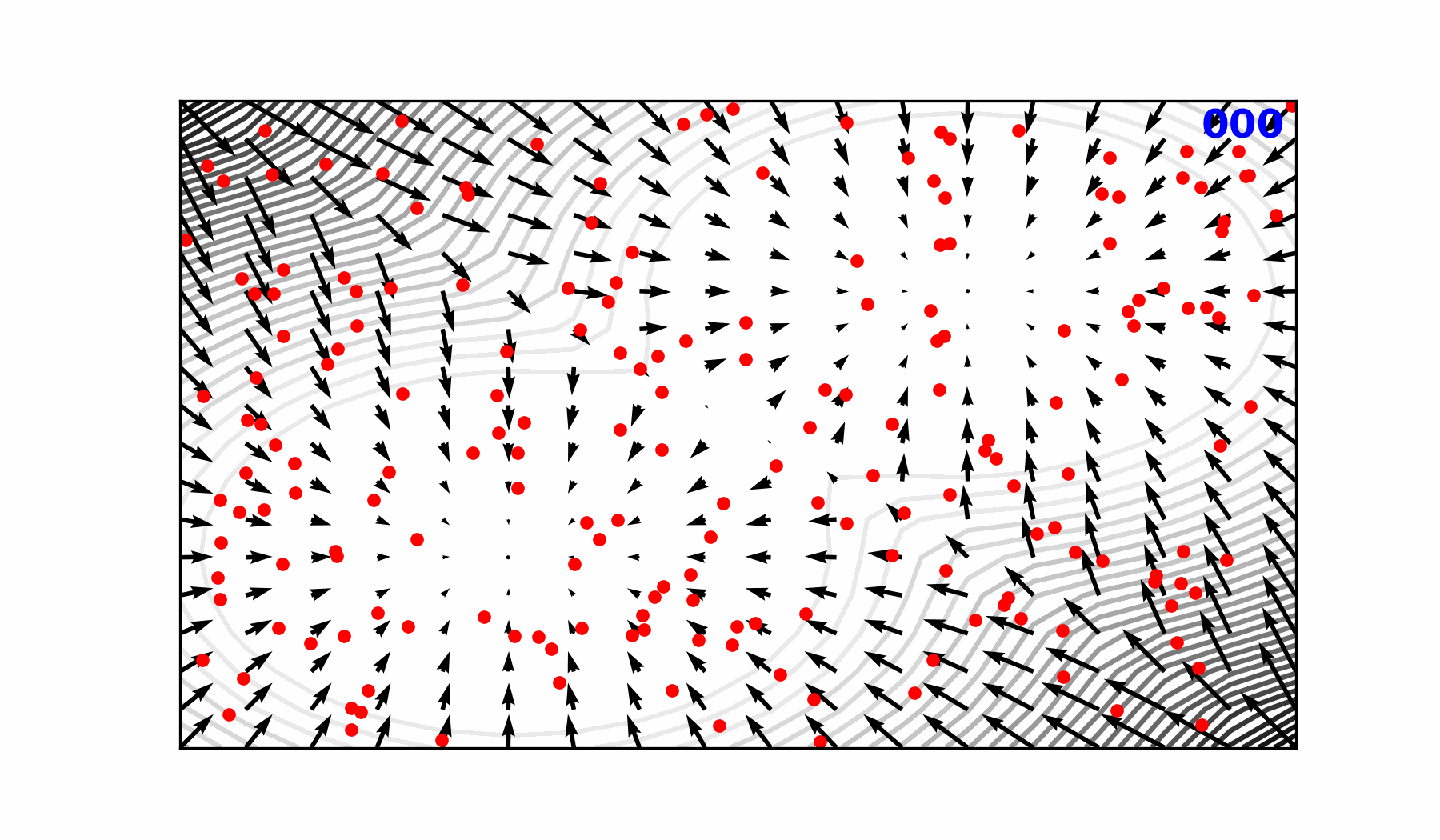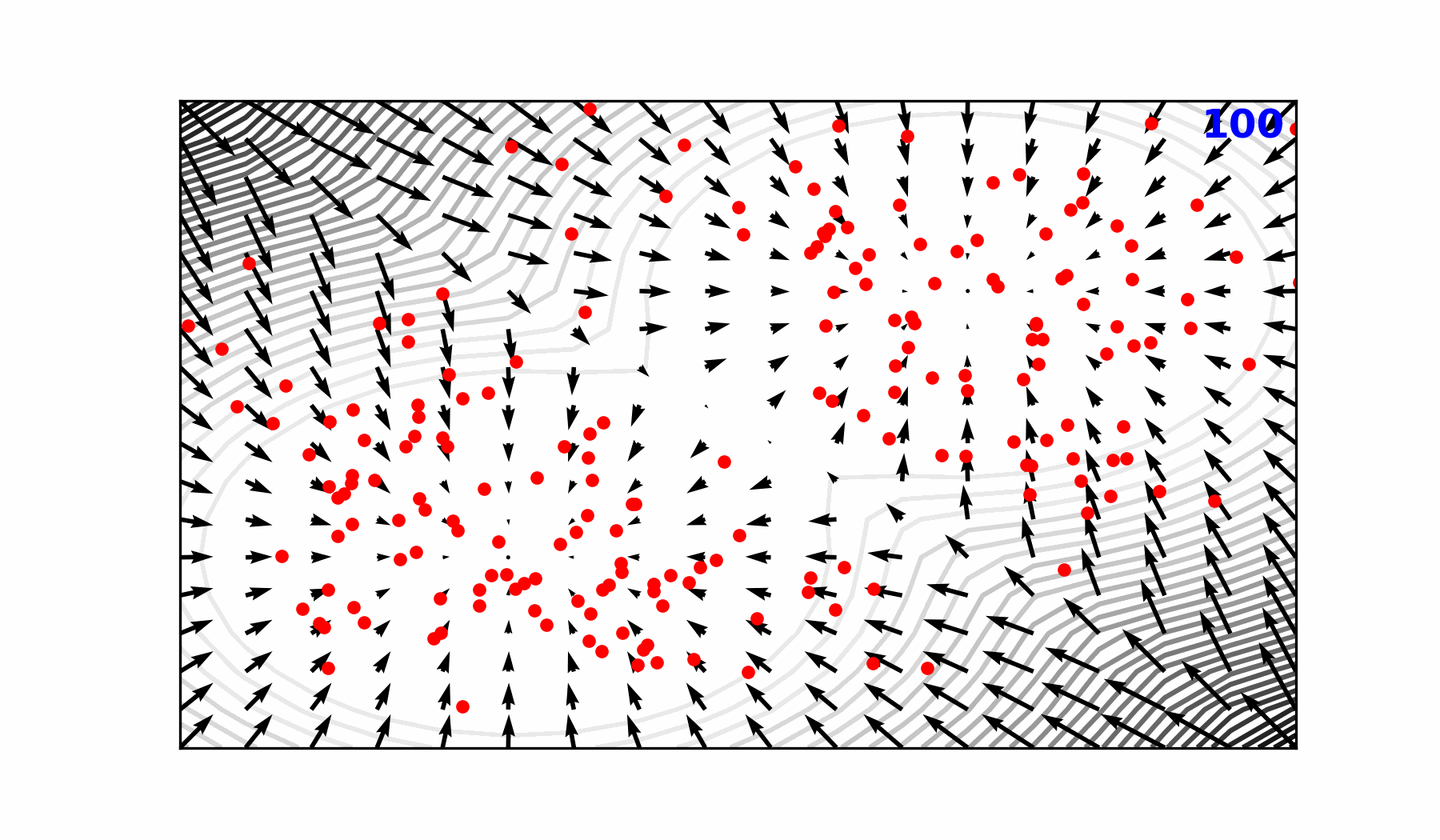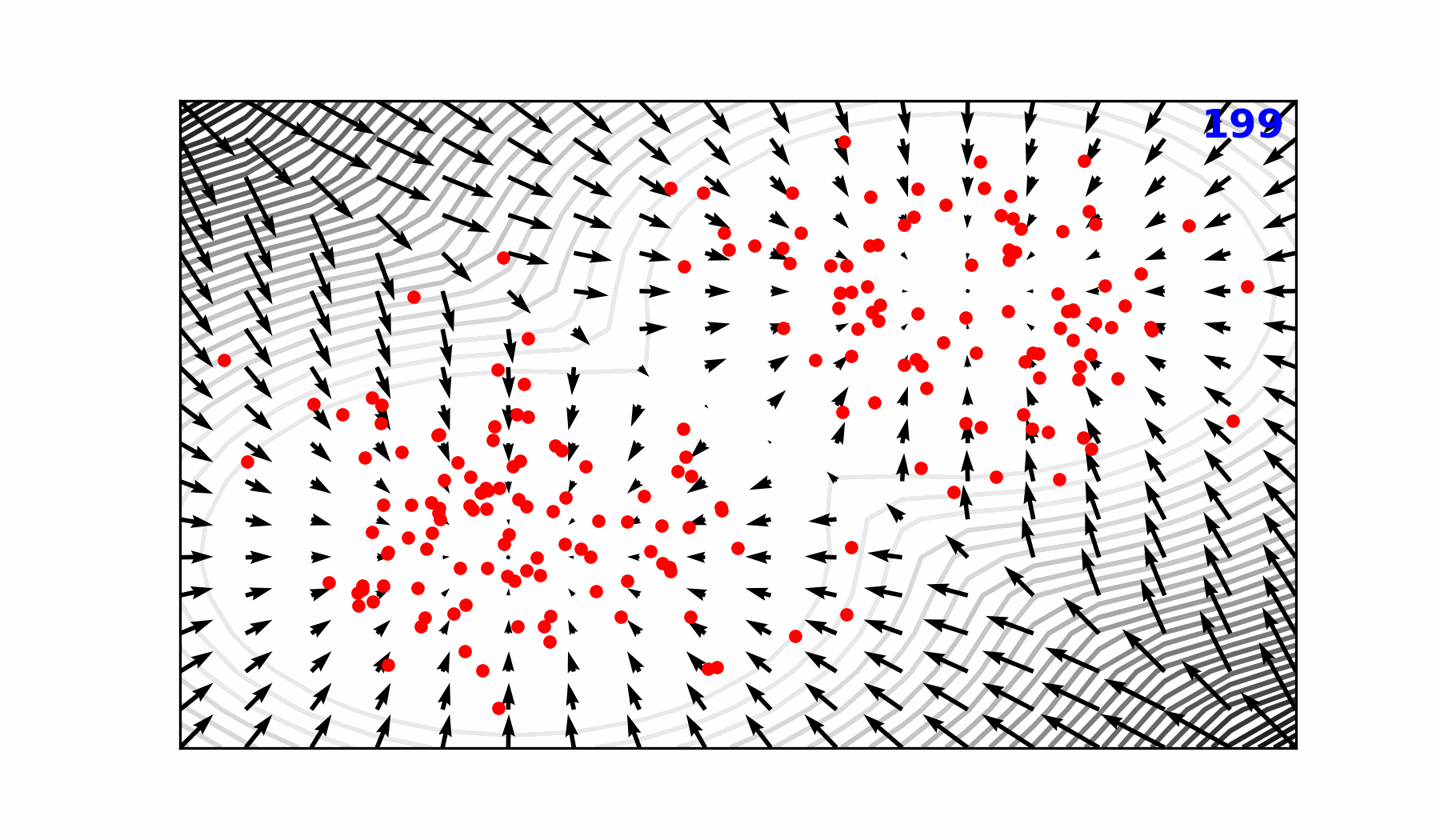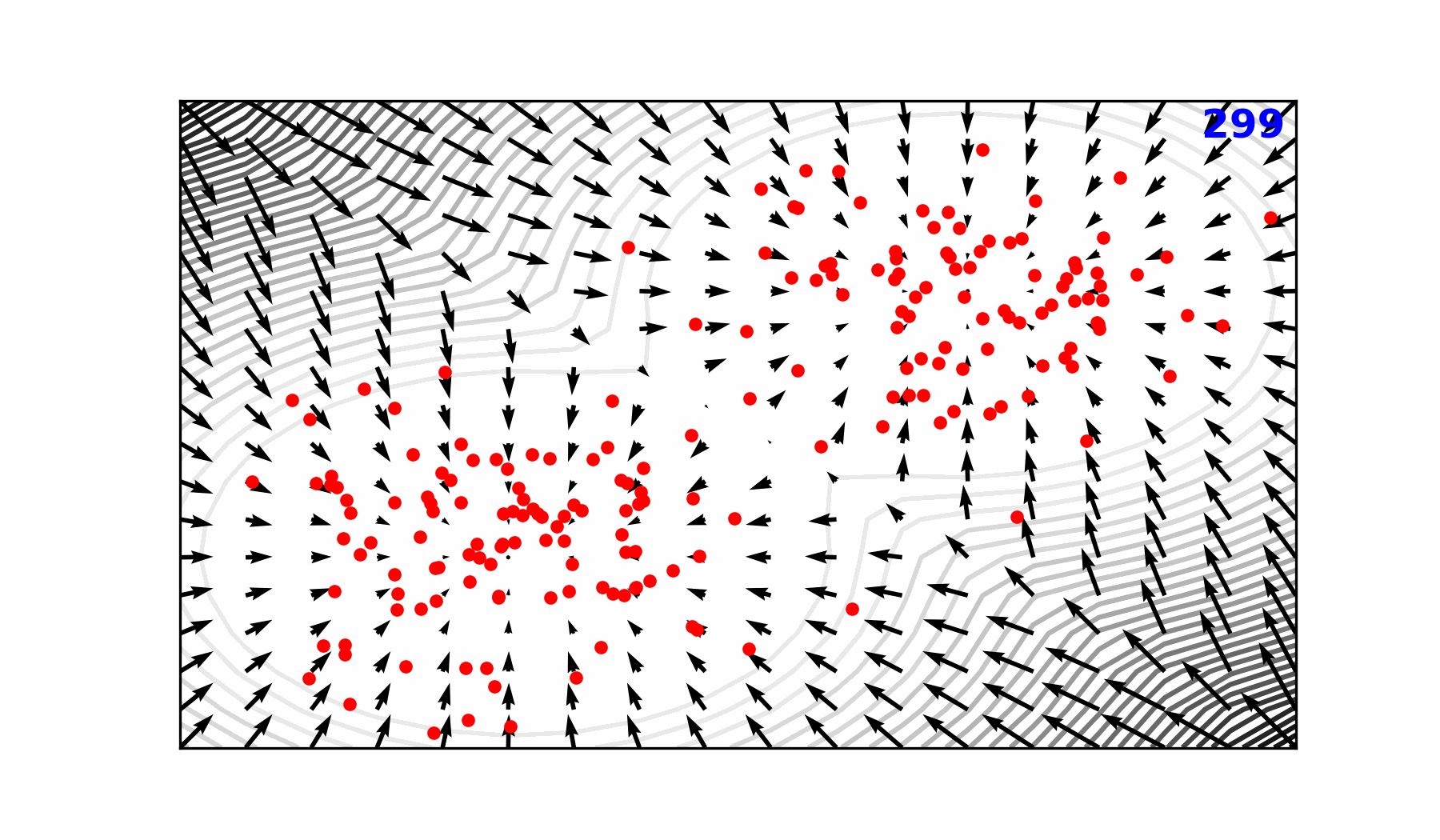
Reverse Diffusion Process ()
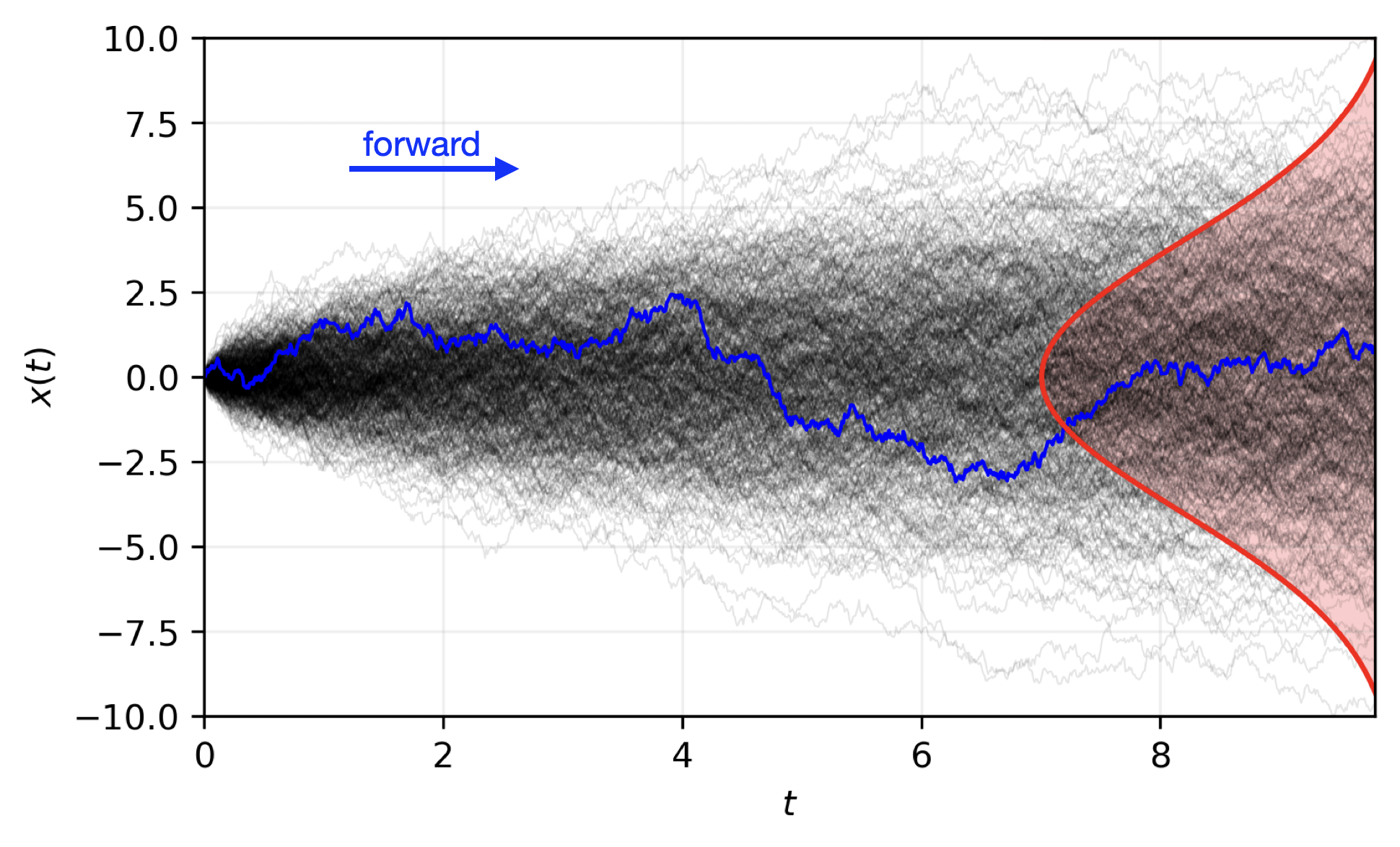
Forward Diffusion Process ()
Sequence-Window-Pipeline Parallelism SWiPe


SWiPe Communication Patterns
AERIS: Scaling Results

AERIS: Scaling Results
Hurricane Laura
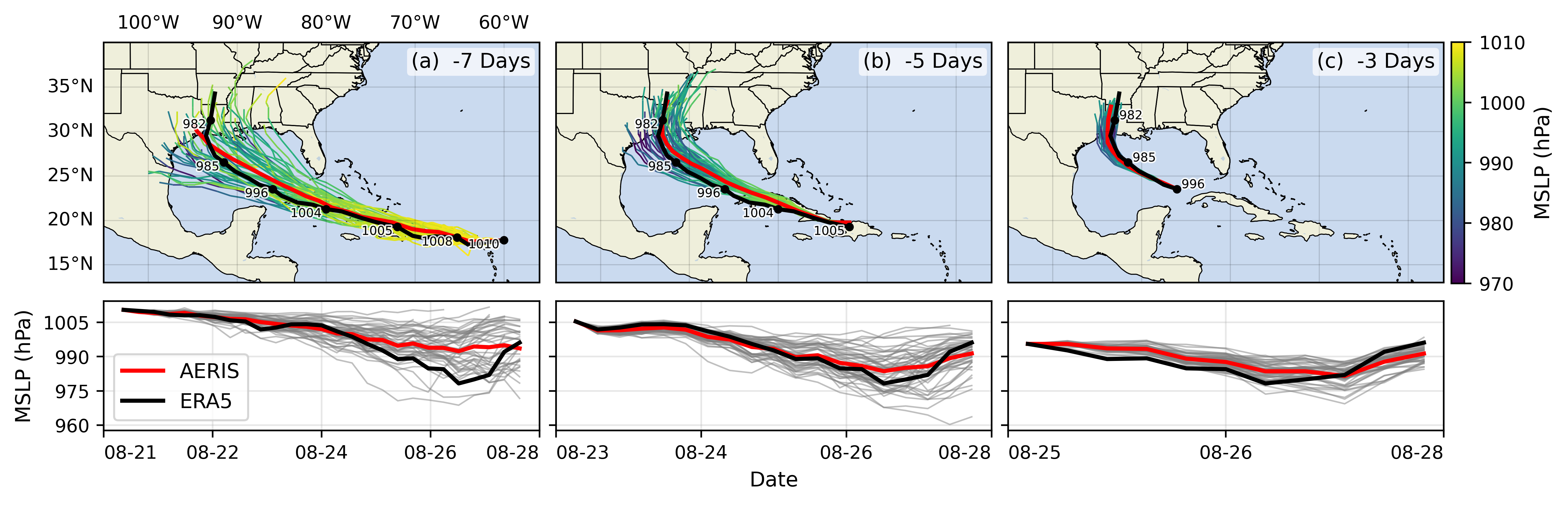
Hurricane Laura tracks (top) and intensity (bottom). Initialized 7(a), 5(b) and 3(c) days prior to 2020-08-28T00z.

